EI、SCI、CPCI等数据库已成为学术评价体系的重要参照指标。论文是否被收录、数据库检索范围及影响因子排名等参数,逐渐成为衡量科研成果的核心要素。值得注意的是,部分研究者存在认知偏差,误认为文献被数据库收录即意味着全文存储其中。这种理解偏差需结合数据库本质属性、功能定位及合作机制进行系统性解析。
EI(工程索引)最初由美国工程信息公司构建,主要服务于工程技术领域文献的索引与检索。SCI(科学引文索引)由美国科学信息研究所开发,现由科睿唯安运营,专注于自然科学领域的文献收录与引文追踪。CPCI(科技会议录引文索引)作为会议论文集的索引工具,同样隶属于Web of Science平台。这些数据库本质上均属文摘型数据库,核心功能在于构建文献元数据网络,而非存储全文内容。每篇文献在数据库中仅呈现标题、作者、机构、关键词、摘要等结构化信息,用于学术导航与引文分析,原始PDF文件仍由出版商独立维护,数据库是不提供下载。
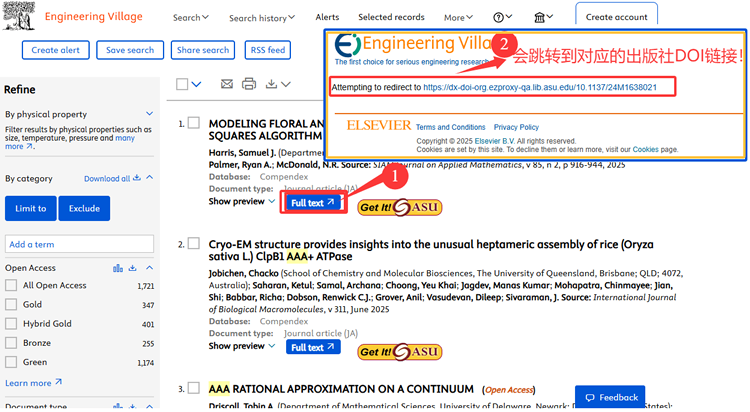
从运行机制来看,EI、SCI、CPCI与出版机构形成互补生态:前者构建文献发现系统,后者掌控内容生产与传播渠道。数据库通过标准化标引流程记录文献元数据,构建可被机器解析的引文网络。这种分工模式既保障了学术成果的全球可及性,又维护了出版商的版权权益。当用户在数据库检索时,搜索结果仅展示文献基本信息,需通过DOI号跳转至出版商平台获取全文,这正是文摘型数据库的技术特性体现。
部分学术会议或期刊在宣传中使用"全文被EI/SCI/CPCI收录"的表述,易引发误解。该表述实质指文献元数据通过结构化标引进入数据库检索系统,而非PDF原文存储。验证收录状态时,建议采用三级核查法:
1、确认数据库索引记录
2、验证出版商平台DOI信息
3、核查机构馆藏情况
研究者需明确区分出版平台与数据库平台的功能差异——前者负责内容质量控制与版权管理,后者承担文献索引与引文分析职能。
当前开放获取运动与预印本平台的兴起,正推动学术传播体系变革。科睿唯安已在Web of Science Core Collection中整合预印本数据,标志着索引系统向全流程覆盖演进。理解数据库的元数据属性与出版生态分工,有助于提升学术信息系统的使用效能,规避常见认知误区。



