本是服务全球科研的“数据金矿”,却沦为低质论文的 “生产车间”,这一荒诞反差,正发生在NHANES、FAERS等五大生物医学数据库身上。
据Science最新研究统计,2021年至今,基于这些公开数据库的论文数量呈“爆发式增长”,但其中超90%来自中国研究人员的成果,竟是靠“替换变量、套用模板”生成的低质内容,既无新科学发现,也无实际应用价值。
这种“灌水式研究”不仅浪费了宝贵的评审资源,更引发学术信任危机,最终迫使Frontiers in Pharmacology、Expert Opinion on Drug Safety 等知名期刊紧急“踩刹车”。
统计学家Matt Spick在担任Scientific Reports副主编时发现,大量利用美国国家健康与营养调查(NHANES)等公开数据的低质论文,正在涌入评审流程。
这些论文模式高度雷同:选取某种健康问题、关联的环境或生理因素,以及特定人群的已公开数据,通过简单替换变量生成所谓的“新发现”。
五大数据库“灌水论文”激增
Nature也在近期的报道中指出,除了NHANES,其他生物医学数据库(UK Biobank、FAERS、GBD和FinnGen)也频繁被这些低质论文利用。

FAERS——FDA的不良事件报告系统,这个我们药物警戒(PV)人最熟悉的数据“金矿”,最近,却被推上了一场前所未有的学术风暴的风口浪尖。大约从2023年开始,关于单个药品与特定不良事件关联的论文数量,出现了“巨型尖峰”(a huge spike)。
这些论文的主要代表刊物——Frontiers in Pharmacology和Expert Opinion on Drug Safety 。
面对这场论文“洪水”,两家期刊终于出手了。
01、Frontiers in Pharmacology
自2025年5月起,要求所有基于健康数据集的研究,都需要进行独立的外部验证。期刊的研究诚信负责人表示:“我们担心的不是使用FAERS本身,而是那些几乎没有增加新科学见解的冗余分析的风险。”
02、Expert Opinion on Drug Safety
行动更为决绝。该期刊在7月下旬,决定完全停止接受使用FAERS数据库进行此类研究的主动投稿。其网站现在明确声明:“此类研究,只有在受到编辑团队特别邀请的情况下,才会被考虑。”
应对“数据库论文”收紧标准
面对这一问题,Journal of Global Health已经率先采取行动,收紧了对基于这些数据库的论文的审核标准。现在,使用开放数据集投稿的作者必须声明过去三年内使用类似数据集发表过多少篇论文,披露是否使用人工智能撰写手稿,并解释其如何排除结果中的假阳性。
为应对“滥用数据集”的趋势,其他期刊和出版商或将效仿Journal of Global Health,引入类似的严格审核机制。
根据Matt Spick、Anthony Onoja等人的研究,2021年-2025年间,有六个数据集的论文数量远超预期增长,其中NHANES、UK Biobank、FAERS、GBD和FinnGen这五个数据源的“模板化”论文爆发式增长。
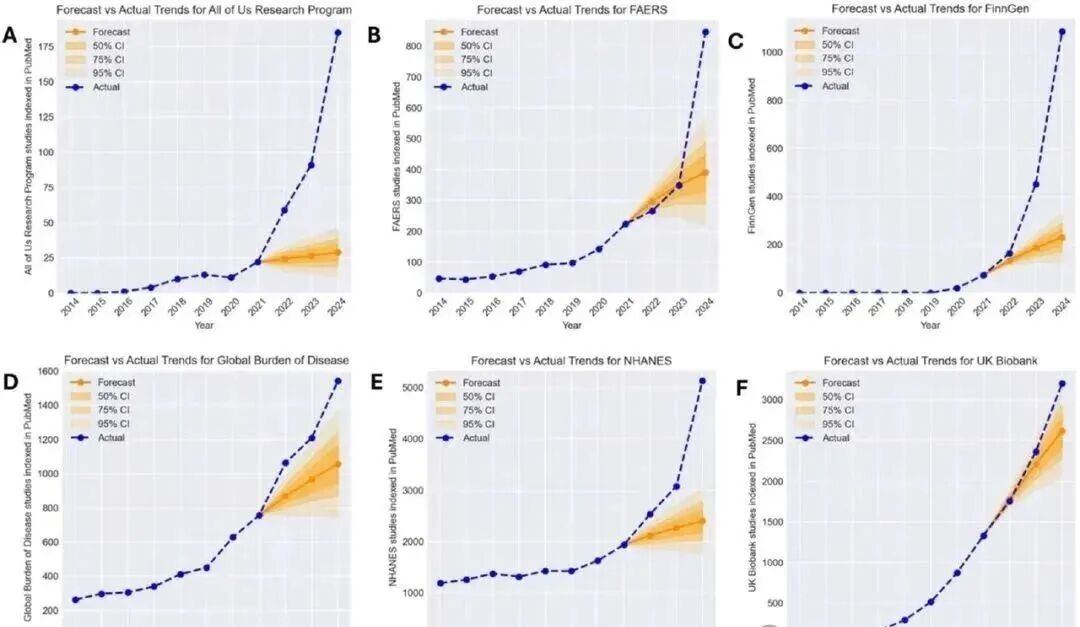
与ARIMA预测相比的六个数据源实际出版数量
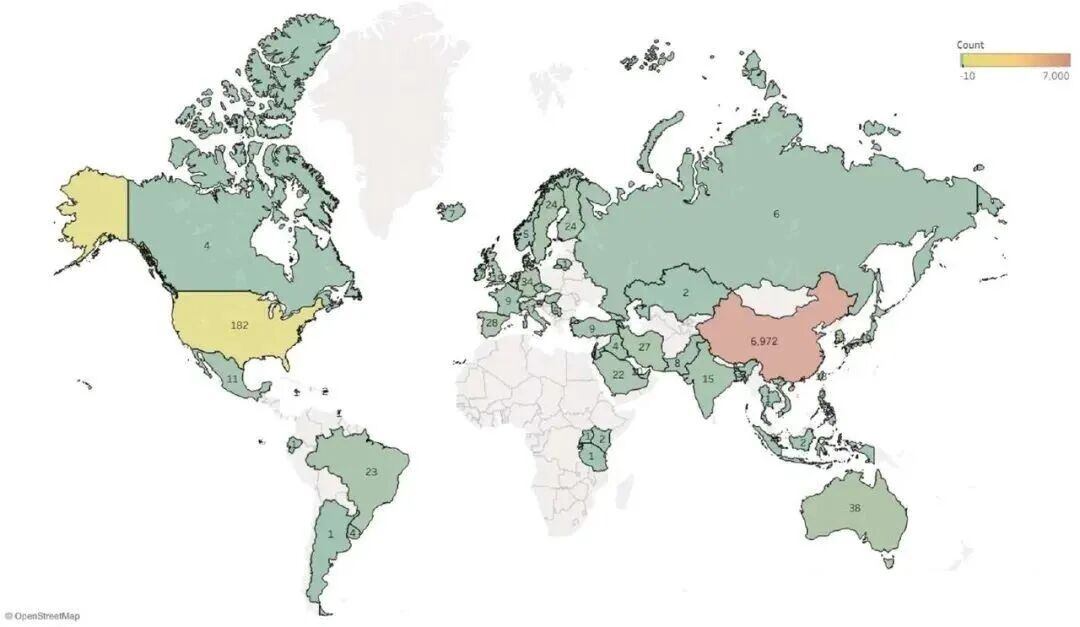
2021年至2024年PubMed中编入索引的论文增加的国家/地区
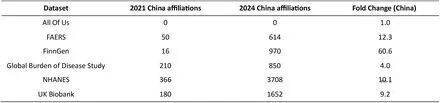
六个数据库的中国论文增长情况
五大生物医学数据库
1. NHANES(美国国家健康与营养检查调查)

基本介绍:由美国疾控中心(CDC)主导,始于1960年代,1999年起转为持续项目,每年调查约5,000名美国代表性人群。
全国代表性:采用分层抽样,过度覆盖老年人、非裔和西班牙裔群体。
数据访问:官网免费开放(XPT格式),可通过R、SAS等工具处理合并。
2. UK Biobank(英国生物样本库)

基本介绍:覆盖50万英国志愿者,历时15年收集基因组、生活方式及健康数据,2025年完成全球最大规模全身体成像项目(10万人)。
多模态整合:结合基因组、蛋白质组、电子健康记录,支持跨维度健康研究。
数据访问:研究者需申请,已支撑1,300+篇论文。
3. FAERS(FDA不良事件报告系统)
基本介绍:FDA用于监测上市后药品安全性的数据库,接收医疗专业人员/消费者的自愿报告。
报告偏差:受药品知名度、媒体报道影响,非全面统计。
数据访问:官网免费开放(TXT格式),含7个(DEMO/DRUG/REAC等)。
4. GBD(全球疾病负担研究)

基本介绍:由华盛顿大学健康指标与评估研究所(IHME)主导,覆盖204个国家/地区、300+疾病、70+风险因素,数据追溯至1990年。
科研产出:多篇《柳叶刀》论文涉及育龄妇女偏头痛、骨关节炎负担等主题。
数据访问:官网免费开放,可通过GBD Compare勾选参数(疾病、地区、年份、指标如DALY/死亡率),直接下载CSV文件。
5. FinnGen(芬兰基因组计划)
基本介绍:2017年启动的公私合作项目,整合50万芬兰人基因组与电子健康记录,利用芬兰人群遗传独特性(基因隔离)解析疾病机制。
独特价值:孟德尔随机化研究:通过遗传变异推断环境因素与疾病的因果关系。
数据访问:通过学术合作申请或等待1年保护期后公开(存于FinnGen Release Portal)。
那些靠“替换变量”“模板化分析”生成的论文,看似利用了公开数据与AI技术的便利,实则毫无新的科学见解,不仅浪费了期刊评审资源,更稀释了优质科研成果的价值,甚至可能误导领域研究方向。
如今,部分期刊通过“外部验证”“停收主动投稿”“强制披露发表史与AI使用情况”等举措收紧标准,是对学术乱象的及时回应,唯有让“重质量、求创新”成为学术共同体的共识,才能让公开数据库回归 “服务科研突破”的本质,让学术生态重回求真务实的正轨。



